Pyroでの変分推論 #
前節で変分推論は、
- 対象の事象の発生過程を確率モデルとしてモデリングする。
- 推定したいパラメータが従う事後確率分布の近似関数(変分関数)を仮定する。
- 変分関数と真の事後関数のKLダイバージェンスを最小化する(=ELBOを最大化する)。
という手順で行うことを説明しました。この節ではPyroを用いて変分推論を具体的に行っていく手順を見ていきます。Pyroでも上の手順をたどっていくことになります。以下の簡単な例を用いてその手順を1つずつ見ていくことにします。
例:袋の中のボールの比率の推論
赤玉と白玉が入っている中身が見えない袋があります。袋の中の赤玉と白玉の数は同数入っている(混合比率=0.5)という事前情報がありますが、実際のところはわかっていません。そこで袋の中からランダムに1つを取り出しそのボールの色を確認後、箱の中に戻すという操作を複数回行います。 この時、10回の試行で赤が6回、白が4回が出た場合、玉の混合比率はどう推論できるでしょうか?Pyroを用いてベイズ推論の枠組みで推論していくことにします。
※ 以下のコードの全体は Githubリポジトリに置いています。
試行データ #
ここでまず上記例の試行結果のデータを作っておきます。
# 試行データ作成
def create_data(red_num, white_num):
red = torch.tensor(1.0)
white = torch.tensor(0.0)
data = []
for _ in range(red_num):
data.append(red)
for _ in range(white_num):
data.append(white)
random.shuffle(data)
data = torch.tensor(data)
return data
data = create_data(6, 4)
確率モデルの構築 #
混合比率の推論に向けて、まず最初に今回の事象が発生する確率モデルを構築します。
$i$回目の試行で取り出される玉の色を表す確率変数を$X_i \in \lbrace\text{赤, 白}\rbrace$とします。例えば混合率(今回は赤玉の比率)を$\theta$とすると、$\theta$に応じて$X_i$の実現値が決まると考えられるでしょう。ベイズ機械学習ではこの混合比率$\theta$も確率的に決まる値であり確率変数$\Theta$の実現値と考えます。つまり取り出される玉の色は以下の過程で決まるとモデル化します。1
- 混合率の実現値$\theta$が、事前確率分布$p(\Theta)$に従って決まる。
- 混合率が$\theta$と決まった条件下で、$\theta$に応じて確率$p(X_i|\Theta=\theta)$で玉の色が決まる。
この確率モデルをグラフィカルモデルで記述すると以下の図のようになります。今回の試行は混合率が$\Theta=\theta$と決まった条件下で各試行間は独立の関係(条件付き独立)となっています。そこで「プレート表現」を使って$N$回の試行を1つにまとめて表現しています。また玉の色は観測されるもので事後確率を考える上での「条件」となるので変数Xに相当するノードが塗り潰されています2。
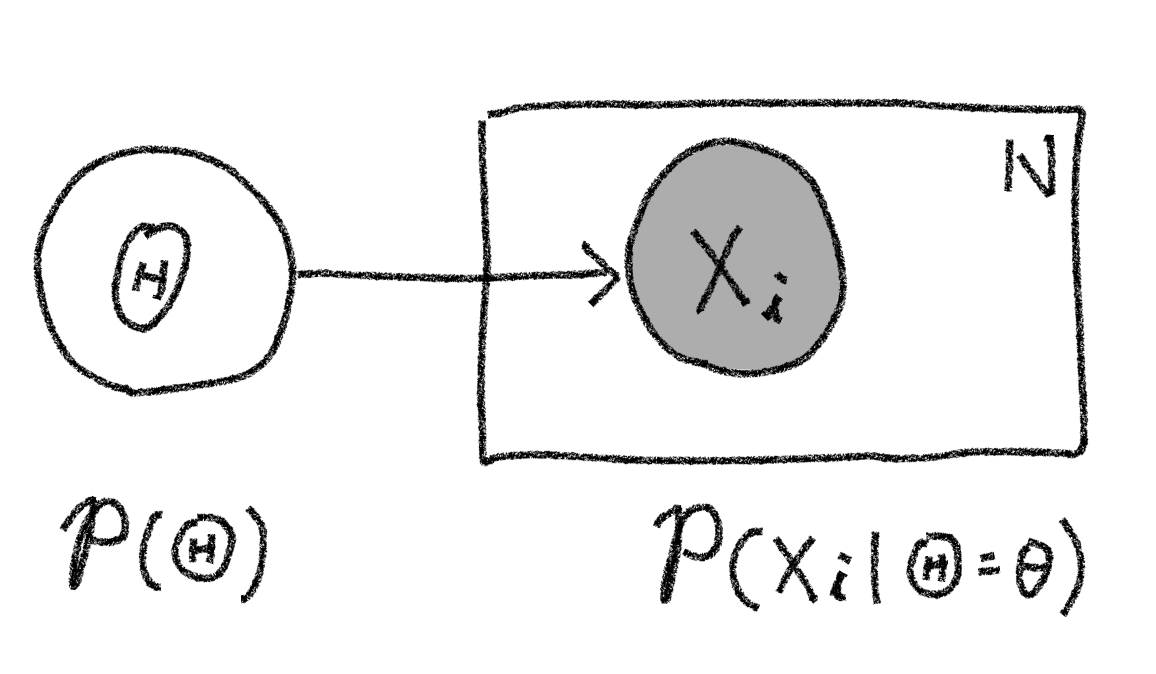
またこの時、試行回数$N$とした時の同時確率分布は以下のように書けます。ここで$x_i$は$i$回目での思考の玉の色の実現値を示しています。 $$p(\mathbf{X}=\mathbf{x}, \Theta=\theta)=\prod_{i=1}^{N} p(X_i=x_i|\Theta=\theta)~p(\Theta=\theta)$$
さて、上記ステップ2.の取り出される色の確率分布は比率$\theta$をパラメータとしたベルヌーイ分布と仮定するのが自然でしょう。つまり $$p(X_i|\Theta=\theta)=\operatorname{Bern}(X_i, \theta)$$
と仮定します。 また今回の例の場合、袋の中には赤玉と白玉同数入っているという事前情報があるのでそれをモデルに取り込むために、比率0.5に穏やかなピークをもつベータ分布 $$p(\Theta)=\operatorname{Beta}(\Theta|\alpha = 2, \beta = 2)$$ と仮定します3。
この確率モデルをPyroで記述してみます。前節で述べたとおりPyroでは確率モデルを確率プリミティブを組み合わせた関数の形で記述します。今回のモデルは以下の様に実装することができます。
# 確率モデルの定義
def model(data):
# 事前確率分布は比率0.5に穏やかなピークを持つ関数を仮定する。
alpha0 = torch.tensor(2.0)
beta0 = torch.tensor(2.0)
f = pyro.sample("Theta", dist.Beta(alpha0, beta0))
# 観測データのプレート定義
with pyro.plate('observation'):
pyro.sample('X', dist.Bernoulli(f), obs=data)
Pyroでは条件付き独立な関係の確率変数を,グラフィカルモデルと同様にplateとしてまとめる機能を持っており、8,9行目ではそれを利用してモデル化しているのに注意してください。
変分関数を仮定 #
今回、我々は玉を取り出した結果をもとに玉の混合比率の確率分布$p(\Theta|X)$を求めようとしています。変分近似ではこの未知の分布をなんらかパラメータを用いて簡単に記述できる分布(変分関数)を仮定してそのパラメータを推定するのでした。ここでは変分関数としてベルヌーイ分布の共役事前分布であるベータ分布を採用し、ベータ分布のパラメータ$\alpha, \beta$を推定する問題に帰着させます。
Pyroでは変分関数の定義もモデルの定義と同様に確率プリミティブを組み合わせた関数の形で記述します。Pyroではこの変分関数を定義する関数をguideと呼びます。
def guide(data):
# 変分パラメータαとβを定義する。
# 初期値は共に10としている。
# また、ベータ分布においてこれらのパラメータは正の値なので`constraints.positive`を指定。
alpha_q = pyro.param("alpha_q", torch.tensor(10.0),
constraint=constraints.positive)
beta_q = pyro.param("beta_q", torch.tensor(10.0),
constraint=constraints.positive)
# 最適化されたパラメータのベータ分布から混合率Θをサンプリングする
pyro.sample("Theta", dist.Beta(alpha_q, beta_q))
guideを定義する際、以下の点に注意する必要があります。
guide関数の引数はmodel関数を定義した際の引数と同一であること。- 学習対象である変分パラメータ(ここでは$\alpha, \beta$)を
pyro.paramを用いて定義します。これは後にELBOの各パラメータの偏微分値を求めるために、requires_gradフラグをTrueにセットしたtorch.tensor型の変数として各変分パラメータを定義していることに相当します。
またここではベータ分布において$\alpha, \beta$は正の値のためconstraint=constraints.positiveとして最適化過程で取りえる値に制約を加えています。
最適化 #
変分関数が定義できたので、その中で変分パラメータとして定義したalpha_qとalpha_qをELBOが最大化するように最適化計算を行います。具体的には以下のコードのように実装します。
# グローバル変数として保存されているパラメータを削除
pyro.clear_param_store()
# Optimizerの定義と設定(Adamの利用が推奨されている)
adam_params = {"lr": 0.002, "betas": (0.95, 0.999)}
optimizer = Adam(adam_params)
# 推論アルゴリズムとLoss値を定義
# ここでは組み込みのELBOの符号反転をLoss値とする`Trace_ELBO()`を利用しています。
svi = SVI(model, guide, optimizer, loss=Trace_ELBO())
# 最適化の逐次計算
# ここではAdamで勾配降下を1000回繰り返すことになる。
n_steps = 1000
losses = []
for step in range(n_steps):
loss = svi.step(data)
losses.append(loss)
if step % 100 == 0:
print('#', end='')
plt.plot(losses)
ここで、最適化を行う前に、pyro.clear_param_store()を実行しています。これはPyroではグローバル変数として各変分パラメータを保持しているため、それを消す処理を行っています。
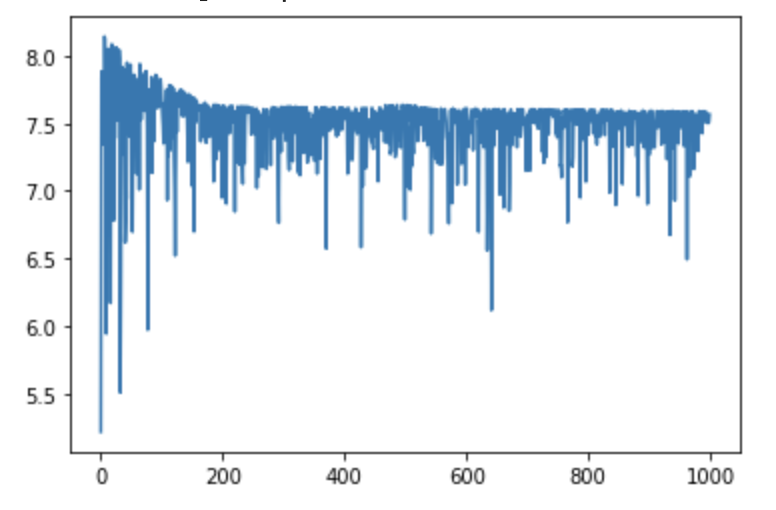
またこのコードでは、svi.step()はLoss値(ELBOの符号逆転値)が返却されるので、Lossの変化をプロットしています。結果は以下の図のようになります。SVI(Stochastic Variational Inference)は確率的勾配降下法(SGD)と同様に計算速度を上げるためにミニバッチで勾配計算を行う4ためLossがランダムに振動していますが、1000回イタレーションを繰り返すと、ELBOが小さいところで落ち着いているのが見てとれます。
この最適化後の変分パラメータは以下のコードのようにpyro.paramで取得できます。
# 最適化後の変分パラメータを取得する
alpha_q = pyro.param("alpha_q").item()
beta_q = pyro.param("beta_q").item()
print("alpha_q = {:.2f}, beta_q = {:.2f}".format(alpha_q, beta_q))
## Output
#alpha_q = 10.55, beta_q = 7.80
我々は混合分布の事後確率分布をベータ分布と仮定していましたから、上記のパラメータを用いて事後確率分布の様子をプロットして確認してみましょう。
# 得られたパラメータを用いて事後確率分布をプロット
x_range = np.arange(0.0, 1.0, 0.01)
estimated_dist = dist.Beta(alpha_q, beta_q)
y = [estimated_dist.log_prob(torch.tensor([x])).exp() for x in x_range]
plt.plot(x_range, y)
得られるグラフは下図のようになります。事後分布$p(\Theta|X)$は0.6付近が最も大きくなっており、これは10回の試行で赤が6回出た観測事象と辻褄が合っているのがわかります。ただし10回の観測ではまだ混合比率に曖昧性があり、確率分布の裾野が比較的広い確率分布となります。
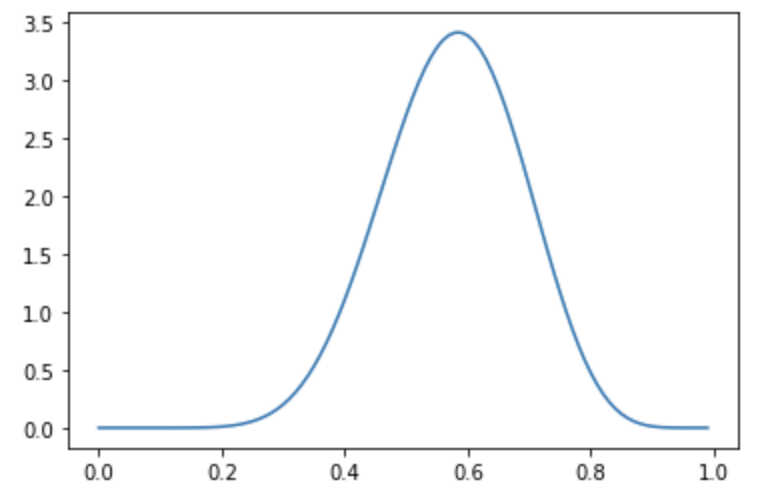
より具体的に今回推論された確率分布の最頻値を求めてみましょう。 計算結果は以下のようになります。 ここで、最頻値0.584となっており、観測結果の0.6より小さくなっているのに注意してください。これは事前確率として0.5をピークに持つ関数を設定していることにより起きています。観測だけを信じると0.6ですが、試行回数が10回程度であればその結果だけを信じて取り込むよりも事前情報の0.5もある程度加味された事後分布になっているという状況です。
# 最頻値を計算
mode = (alpha_q - 1) / (alpha_q + beta_q - 2)
print("mode = {:.3f}".format(mode))
# 平均値を計算
mean = alpha_q / (alpha_q + beta_q)
# 標準偏差を計算
factor = beta_q / (alpha_q * (1.0 + alpha_q + beta_q))
std = mean * np.sqrt(factor)
print("infered ratio = {:.3f} +- {:.3f}".format(mean, std))
## Output
# mode = 0.584
# infered ratio = 0.575 +- 0.112
さらに観測回数を増やして1000回の試行でそのうち赤が600回、白が400回取り出された場合はどのような混合比率の事後分布になるでしょうか?
試行データ作成時にdata = create_data(600, 400)としてデータを作成して同様の推論を行ってみます。
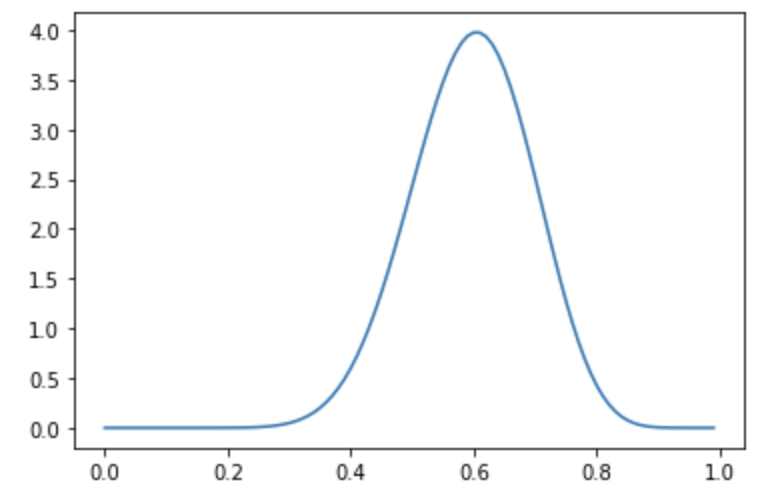
すると結果の事後分布は下記のような形となり、10回の時よりも混合比率が0.6である確信が強まり、確率分布の裾野が10回の思考の場合よりも狭まっているのがわかります。
以上、Pyroを用いて簡単な例での変分推定のやり方を見てきました。今回のコードは Githubに配置していますので参考にしてみてください。